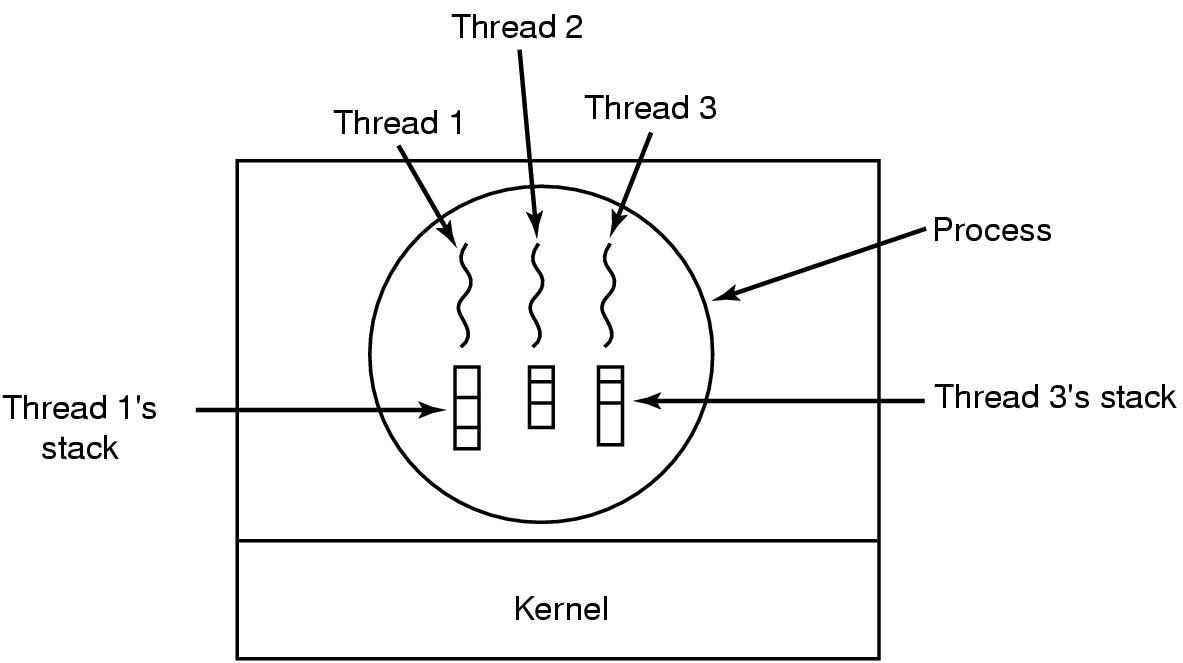
Jos jokin sovellus on muodostunut useammasta itsenäisestä suorituspolusta, on sovellus pitänyt koostaa käyttäen useaa prosessia. Hankaluutta aiheuttaa se, että oletusarvoisesti jokaisella prosessilla on oma itsenäinen muistiavaruus eli tiedon jakaminen yhden sovelluksen muodostavien prosessien kesken saattaa olla hiukan hankalaa. Kuten edellisillä viikoilla olemme nähneet, niin tiedon jakaminen prosessien kesken ei Unix-tyyppisissä käyttöjärjestelmissä tuota suurta ongelmaa esim. jaettujen muistialueiden ansiosta.
Usein olisi helpompaa ja selkeämpää, jos samaa muistia voisi käyttää useampi rinnakkainen, samaan sovellukseen liittyvä suorituspolku. Modernimpi 1980-luvun jälkeen yleistynyt näkemys prosessista on se, että prosessi sisältää joukon resursseja (muisti, avoimet tiedostot, putket, ym.), ja prosessin sisällä on useita rinnakkaisia säikeita (engl. thread), joiden suoritus etenee itsenäisesti. Säikeet siis jakavat prosessin muistin. Tällöin on helppo tehdä useasta säikeestä koostuvia sovelluksia, jotka kaikki näkevät saman muistialueen. Tämä onnistuu ilman erityisiä ohjelmallisia temppuja (jaettuja muistialueita, putkia, signaaleja ym) mitä prosessien väliseen tiedon jakoon tarvitaan.
Säikeiden käyttö on edullista myös siksi, että säikeet ovat prosesseja kevyempi ratkaisu niiden KJ-tasolle aiheuttaman kuormituksen suhteen. Säikeistetyn prosessin säikeiden skeduloiminen on kevyempää kun vastaavan prosessimäärän skeduloiminen jos lasketaan se, kuinka paljon käyttöjärjestelmä kuluttaa aikaa skedulointiin ja suoritettavan säikeen/prosessin vaihtoon. Ero voi olla todella huomattava, riippuen siitä miten säikeet on KJ:n tasolla toteutettu. Linuxissa säikeiden ja prosessien välillä ei ole yhtä suurta suorituskykyeroa kuin jossain muissa järjestelmissä.
Yhden prosessin säikeet siis jakavat saman muistiavaruuden sekä joukon muita resursseja, kuten avoimena olevat tiedostot. Koska säikeiden suoritus on toisistaan riippumaton, tarvitaan jokaiselle säikeelle oma kopio CPU:n rekisterien arvoista, erityisesti oma ohjelmalaskuri, sekä oma pino. Jokaisella säikeellä on oma tila, eli säie on joko running, runnable tai sleeping -tilassa. Säikeiden tilat siis vastaavat täysin sitä mitä aiemmin sanoimme prosessin tiloista.
Useimmissa nykyisissä käyttöjärjestelmissä tilanne on se, että prosesseilla on oletusarvoisesti yksi säie. Jos ohjelmoidaan "vanhaan tapaan", prosessille ei edes luoda muita säikeitä ja kaikki etenee niin kun mitään säikeistystä ei edes olisi olemassa.
Esim. Unixeissa prosessiin voidaan luoda uusia säikeitä käyttämällä pthread.h-kirjastossa määritellyn säie-API:n funktioita.
Säikeiden skedulointi tapahtuu siis prosessien sisällä.
Säikeille ei voida antaa aikaviipaleita samaan tapaan kuin prosesseille.
Tästä seurauksena on se, että prosessin yksittäinen säie voi jatkaa suoritusta
niin kauan kun haluaa. Yleensä käytössä on kirjastorutiini
Prosessitason säikeiden hyviä puolia
Eli vaikka prosessin muut säikeet voisivat jatkaa, ei se onnistu, sillä
prosessi, jonka yksikin säie blokkaa, on KJ:n suhteen sleeping-tilassa.
Tämä tekee ohjelmakirjastona toteutetut säikeet
käyttökelvottomiksi tietynlaisiin sovelluksiin.
KJ:n ulkopuolella toteutetut säikeet olivat suosittuja säikeiden historian
alkuvaiheissa. Nykyään on kuitenkin siirrytty useimmiten säikeisiin, jotka
myös käyttöjärjestelmä tuntee.
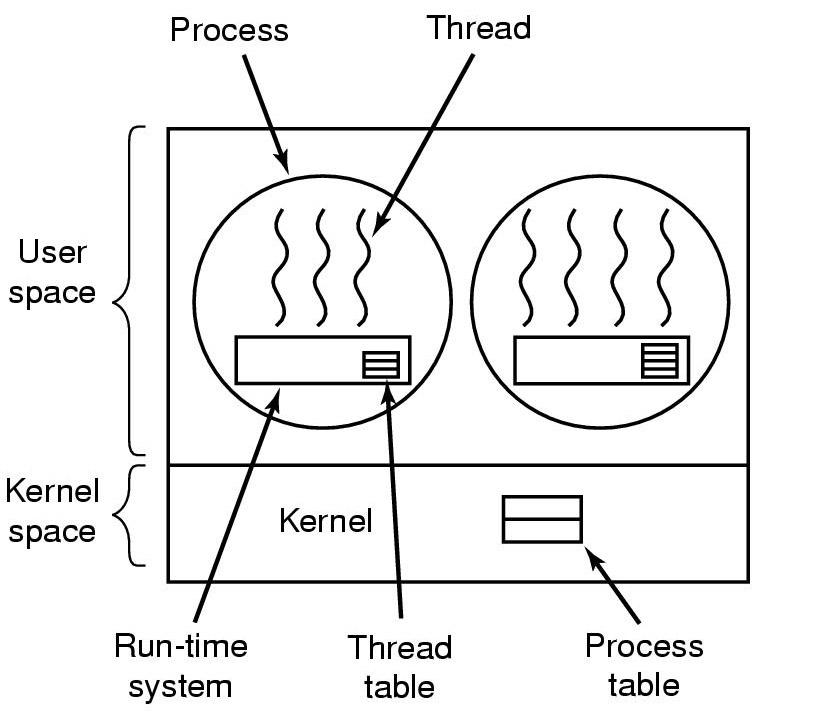
KJ pitää kirjaa sekä prosesseista että säikeistä.
Prosessikirjanpito tallettaa prosessikohtaiset tiedot, mm. muistiavaruuden ja
avoimet tiedostot sekä tiedon prosessiin kuuluvista säikeistä.
Säiekirjanpito tallettaa kaiken säiekohtaisen tiedon, eli CPU:n rekisterien
tilan sekä säikeen oman pinon tiedot.
Säikeiden skedulointi tapahtuu KJ:n toimesta. KJ:n skeduloinnin yksikkö ei
enää ole prosessi vaan säie.
Hyvänä puolena KJ-tason toteutuksessa on se, että Vaikka yksi prosessin
säikeistä suorittaisi odotusta vaativan systeemikutsun, muut prosessin säikeet
säilyvät suorituskelpoisena. Huonona puolena se, että KJ:n tasolla
toteutettuna säikeet ovat CPU:n kulutuksen kannalta hieman raskaammat kun
prosessin sisällä toteutetut säikeet eli suorituksessa olevan säikeen
vaihtaminen sekä uuden säikeen luominen vie hieman enemmän resursseja KJ:n
tason säikeissä.
Esim. Linuxissa ja Windowsissa säikeet on toteutettu KJ:n tasolla.
Käyttöjärjestelmäytimen tasolla tarkastellen Linuxissa ei oikeastaan edes ole
säikeitä. On ainoastaan prosesseja, mutta on mahdollista määritellä joukko
prosesseja toimimaan siten, että ne toimivat kuten säikeet, eli jakavat
muistiavaruuden ja muut resurssit. Ohjelmointikielessä käytetyt primitiivit
määräävät sen, minkälaisia prosesseja ydin luo. Jos käytetään fork:ia, luodaan
"normaali" prosessi, joka saa oman muistiavaruuden. Jos taas käytetään
säikeen luovaa pthread_create:a, luodaan prosessi, joka sijoitetaan samaan
muistiavaruuteen missä kutsun suorittanut prosessi on. Näinollen
Linux toimii siis säikeiden ja prosessien suhteen juuri niinkuin speksit
(esim. Posix-standardi) määrittelee, mutta alla oleva toteutus on
ovelampi kun useissa muissa käyttöjärjestelmissä, joihin säikeet on
sisällytetty "liimaamalla" ne prosessien kylkeen.
Java:n säikeiden toteutus eri alustoilla saattaa olla erilainen. Esim.
Linuxissa tilanne on se, että Java 2 JRE 1.2:n asti virtuaalikonetta
ajettiin yhden prosessin sisällä ja ohjelman säikeet toteutettiin
puhtaasti yhden prosessin sisällä prosessitason säikeinä. Java 2 JRE 1.3:sta
alkaen säikeet on toteutettu oikeina KJ-tason säikeinä.
Nykyisin vallalla oleva prosessoriteknologia eli moniytimiset prosessorit
(dual core, quad core) tehostavat yksittäisen sovelluksen suorittamista vain
jos sovellus on toteutettu monisäikeisesti (tai useana prosessina).
Sovellusten monisäikeisyyteen pitää todennäköisesti tulevaisuudessa
panostaa yhä enemmän.
Sovelluksen toteuttaminen monisäikeisenä on kuitenkin teknisesti erittäin
haastavaa. Joitain asioita on helppo laittaa omaksi säikeekseen, kuten esim.
dokumentin automaattinen tallettaminen 10 minuutin välein. Paljon
CPU-tehoa vaativat tehtävän säikeistäminen onkin usein paljon hankalampaa
ellei tehtävää voida pilkkoa helposti toisistaan erillisiksi osiksi.
Kaikkein suurin säikeistyksen (ja kaiken muunkin rinnakkaisuutta sisältävän
ohjelmoinnin) hankaluus on kuitenkin se, miten säikeet saadaan keskenään
synkronoiduksi ja niiden toiminta koordinoitua siten, että säikeiden käyttämä
data pysyy koko ajan konsistentissa muodossa ja etteivät säikeet joudu
vahingossa ikuiseen odotukseen, eli lukkiumatilaan (engl. deadlock).
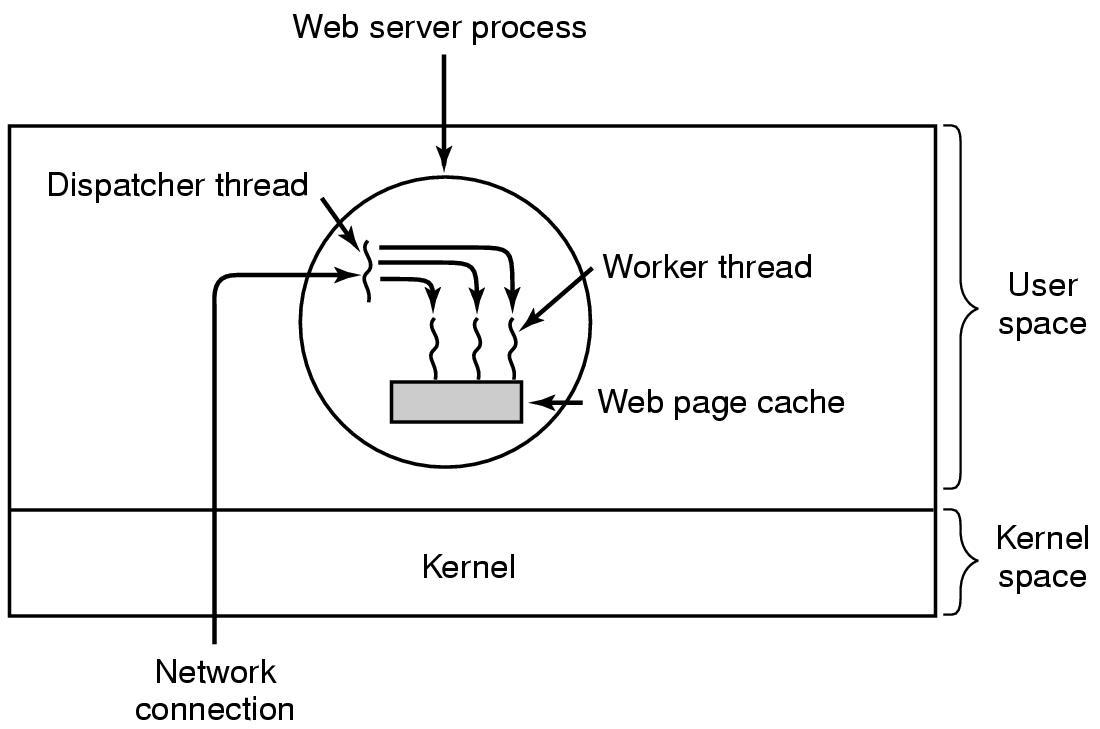
Yksi esimerkki helposti säikeistyvästä ohjelmasta on www-palvelin,
joka voidaan toteuttaa säikeiden avulla esim. seuraavasti.
Yksi säie kuuntelee asiakkailta tulevia yhteyspyyntöjä.
Avattu yhteys ohjataan jollekin työntekijäsäikeistä.
Palvelimen nopeutta tehostava sivuvälimuisti on kaikille säikeille näkyvässä
muistissa. Työntekijäsäie katsoo ensin onko sivu välimuistissa, jos ei niin
tehdään levyoperaatio ja haetaan haluttu sivu. Jos kyseessä on dynaamisten
sivujen näyttäminen, työntekijäsäie voi tehdä tarvittaessa kyselyn
tietokantaan. Koska jokaista www-pyyntöä hoitaa oma säie, ei esim. yhden
sivupyynnön aiheuttama aikaavievä tietokantaoperaatio haittaa muiden
yhteyksien palvelemista.
Palvelimen ohjelmointi ilman säikeitä olisi hankalaa. Linuxilla se tosin
hoituisi kohtuullisen hyvin myös prosesseja ja esim. jaettua muistia
käyttäen.
Linuxissa säikeet ovat teknisesti ottaen prosesseja. Siksi jokaisella
säikeellä on oma PID. Säikeet saa näkyviin myös ps-komennolla käyttäen
optiota -m.
Esimerkissä 11-2.c luodaan kolme säiettä.
Säikeet saavat parametrina kokonaisluvun, jonka arvoa ne tulostavat ruudulle
muutaman kerran.
Tällä kertaa säikeelle välitetään parametri. Parametri on tyypiltään int,
joten se on castattava oikeaan tyyppiinsä. Säikeen suorittama funktio
tulostaa ruudulle parametrinaan saamansa lukeman 50 kertaa.
Säikeen aloitusfunktiolla on kaksi muuttujaa, i ja param. Kaikki funktioiden
sisällä määritellyt muuttujat varataan pinon sisältä ja koska kaikilla
säikeillä on oma pino, on kaikilla säikeillä funktioiden sisäisistä
muuttujista omat kopionsa. Sama pätee myös main-funktion sisällä
määriteltyihin muuttujiin. Jaettuihin muuttujiin pääsemme vasta seuraavassa
esimerkissä.
Funktioiden ulkopuolella määritellyt globaalit muuttujat siis näkyvät kaikille
säikeille. Globaalien muuttujien käyttäminen ei kuitenkaan ole yleensä
kovin viisasta. Parempi vaihtoehto säikeiden jakamien muuttujien
tallentamiselle on varata muistialue mallocilla ja välittää osoitin
varattuun muistialueelle kaikille sitä tarvitseville säikeille.
Näin toimitaan ohjelmassa 11-4.c, missä säikeet
käsittelevät oletussäikeen mallocilla varaamaa 1000000 paikkaista taulukkoa.
Ohjelmassa on kaksi säiettä,
joista toinen etsii taulukon pienimmän ja toinen suurimman luvun.
Jaetun taulukon alun osoite välitetään säikeille parametrina.
Säikeet palauttavat löydetyn pienimmän ja suurimman arvon oletussäikeelle
lopetuksen yhteydessä funktion pthread_exit parametrina. Parametrin tyyppi
on void-osoitin, joten paluuarvo on castattava kutsun ajaksi.
Jos säie palauttaisi osoittimen, esim. dynaamisesti varatun int-taulukon,
toimittaisiin ohjelman 11-5.c tapaan:
Säikeiden toteutus KJ:n tasolla
Nykyään yleisin tapa on toteuttaa säikeet siten, että KJ on täysin tietoinen
säikeiden olemassaolosta.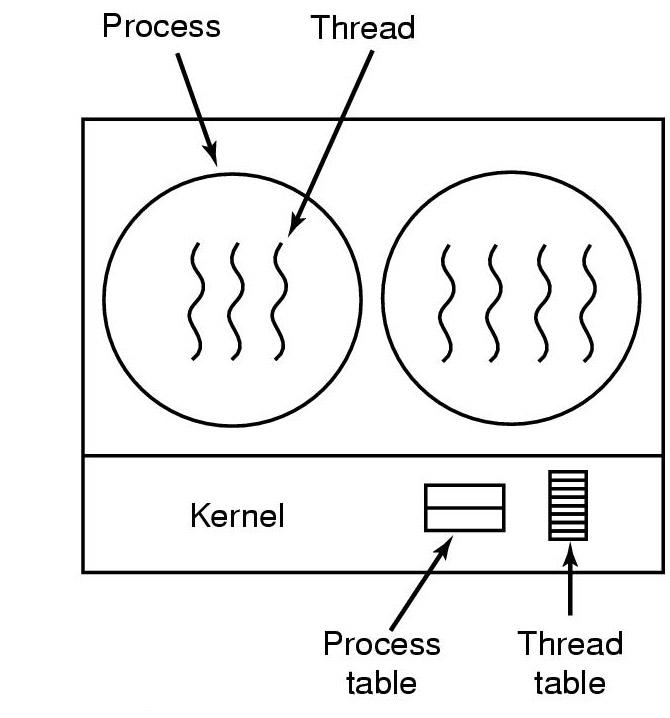
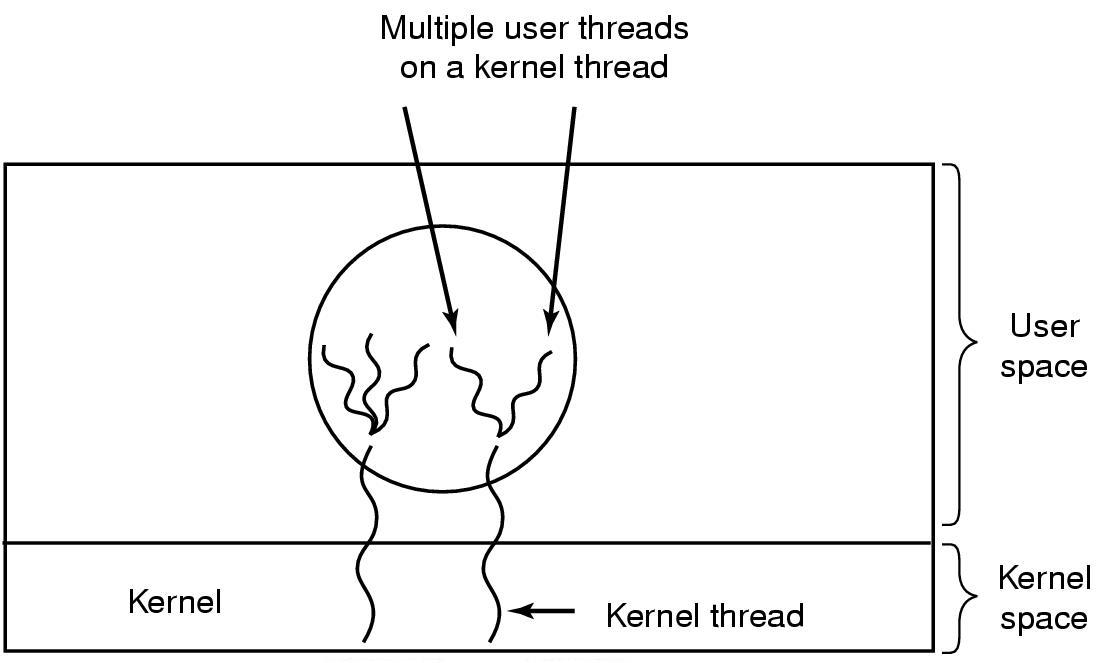
Hybriiditoteutus
Esim. Sunin Solaris KJ:ssä (Unix klooni) on toteutettu sekä KJ:n että
prosessitason säikeet. Jokaista prosessia kohti varataan joukko KJ-tason
säikeitä. Ohjelmoija käyttää KJ:n ulkopuoleisia prosessitason säikeitä.
Prosessitason säikeitä suoritetaan KJ-tason säikeiden sisällä.
Kullakin prosessilla voi olla prosessitason säikeitä enemmän kun prosessia
varten varattuja KJ-säikeitä. Jos jokin prosessitason säie blokkaa,
voidaan muita prosessitason säikeitä suorittaa muiden prosessille varattujen
KJ-säikeiden sisällä.
Säikeiden käyttö
Usein ohjelma kannattaa rakentaa käyttäen useampia säikeitä. Esim.
taulukkolaskenta voitaisiin säikeistää siten, että yksi säie kuuntelee
käyttäjän komentoja (kirjoitettu teksti ja valikkojen kautta annetut komennot)
Jos talletetaan tiedosto levylle, kannattaa tallentamista varten luoda uusi
säie, jotta muu sovellus voi jatkaa häiriintymättä.
Kaavojen laskemisen ja siitä johtuvan tietojen päivittämisen voi hoitaa
oma säie. Jos käytössä on dokumenttien automaattinen tallennus esim. 10
minuutin välien, tämän voi hoitaa oma 10min välein heräävä säie.
Säikeistettyjen ohjelmien tekeminen
Säikeiden ohjelmoiminen tapahtuu käyttämällä pthread.h-kirjastoa. Tutkitaan
ohjelmaa 11-1.c. Ensin määritellään koodi, mitä säikeet
alkavat käynnistyessään suorittamaan. Säie aloittaa aina funktiolla, joka
saa yhden void * parametrin sekä palauttaa void * -muotoisen arvon, eli void
osoitteen. Säikeen aloitusfunktio voi kutsua mitä tahansa ohjelmassa
määriteltyä funktiota. Ohjelma määrittelee kaksi erilaista aloitusfunktiota:
#include < pthread.h>
#include < stdio.h>
// säikeen aloitusfunktio, paluuarvo ja ainoa parametri aina tyyppiä void *
void *ownthread(void *arg){
printf("Olen säie\n");
pthread_exit(NULL);
}
void *ownthread2(void *arg){
printf("Olen erilainen säie\n");
pthread_exit(NULL);
}
Mainissa käynnistetään kolme säiettä. Käynnistys tapahtuu funktiolla
pthread_create(), josta toistaiseksi käytetään vain ensimmäistä ja
kolmatta parametria. Ensimmäisenä osoitin pthread_t-tyyppiseen muuttujaan,
joka saa arvokseen säietunnisteen. Kolmas parametri on funktio, jota säie
alkaa suorittamaan. Tämän jälkeen prosessin oletussäie (eli mainin aloittava
suoritus) alkaa odottamaan säikeiden lopettamista funktiolla
pthread_join(), jonka ensimmäisenä parametrina säie, jota odotetaan.
Tässä vaiheessa emme tarvitse funktioiden muita parametreja ja niiden arvoksi
asetettu NULL.
int main(void){
// muuttujat säietunnisteille
pthread_t tid1, tid2, tid3;
// käynnistetään kolme säiettä
pthread_create( &tid1, NULL, ownthread, NULL );
pthread_create( &tid2, NULL, ownthread, NULL );
pthread_create( &tid3, NULL, ownthread2, NULL );
// odotetaan säikeiden lopetusta
pthread_join( tid1, NULL );
pthread_join( tid2, NULL );
pthread_join( tid3, NULL );
return 0;
}
Säikeitä sisältäviä ohjelmia käännettäessä on gcc:lle annettava optio
-lpthread, jotta säikeet toteuttava koodi osataan linkittää mukaan.
void *ownthread(void *arg){
// parametri castataan oikeaan tyyppiinsä
int param = (int)arg;
int i;
for ( i=0; i < 50000000; i++ )
if ( i%1000000 == 0 ) {
printf("%d ",param);
fflush(stdout);
}
// fflush varmistaa että tulostettu numero menee heti ruudulle, näin ei
// prinf:llä välttämättä tapahdu, jos tulostuksessa ei ole rivinvaihtoa
pthread_exit(NULL);
}
Mainissa säikeet käynnistetään. Säikeille välitettävä parametri tulee
pthread_creat:issa viimeiseksi. Kutsun ajaksi parametri castataan tyyppiin
void-osoittimeksi.
int main(void){
pthread_t tid1, tid2, tid3;
// käynnistetään säie ja annetaan parametriksi int-luku 1
// funktiokutsun ajaksi parametri castataan tyypiin void *
pthread_create( &tid1, NULL, ownthread, (void *)1 );
// lisää säikeitä kaikille oma parametri
pthread_create( &tid2, NULL, ownthread, (void *)2 );
pthread_create( &tid3, NULL, ownthread, (void *)3 );
// odotetaan säikeiden lopetusta
pthread_join( tid1, NULL );
pthread_join( tid2, NULL );
pthread_join( tid3, NULL );
printf("\n");
return 0;
}
Ohjelmassa 11-3.c säikeet käyttävät jaettua muuttujaa.
Säie 1 kasvattaa muuttujan arvoa 100000000 kertaa. Säie 2 tulostaa
muuttujan arvon 20 kertaa ja viivyttelee välillä. Säikeet käynnistetään
yhtä aikaa eli muuttujan kasvatus ja arvon tulostelu etenevät yhtäaikaisesti.
Jotta muuttuja näkyy kaikille säikeille, täytyy se määritellä funktioden
ulkopuolella.
#include
Pääohjelma nollaa muuttujan aluksi, käynnistää säikeet ja säikeiden lopetettua
tulostaa muuttujan arvon.
int main(void){
pthread_t tid1, tid2;
// oletussäie nollaa jaetun muuttujan x
x = 0;
pthread_create( &tid1, NULL, th1, NULL );
pthread_create( &tid2, NULL, th2, NULL );
pthread_join( tid1, NULL );
pthread_join( tid2, NULL );
printf("lopussa x = %d\n",x);
return 0;
}
Koska vain yksi prosessi kirjoittaa jaettuun muuttujaan, ei muuttujan
yhteiskäytöstä synny ongelmia. Jos molemmat muuttaisivat muuttujan arvoa
samaan tapaan kun prosessit esimerkissä 9-3.c
olisi tilanne toinen ja säikeiden olisi suojattava jaettu muuttuja.
Palaamme jaettujen muuttujien suojaamiseen ja säikeiden synkronointitapoihin
seuraavalla viikolla.
// säie etsii pienimmän arvon parametrina saamastaan globaalista taulukosta
// arvo palautetaan säikeen lopetuksen yhteydessä
void *min(void *arg){
int *values = (int *)arg;
int i;
int min = values[0];
for ( i=0; i < N; i++ )
if ( values[i] < min ) min = values[i];
// paluuarvon tyypin oltava void *, joten int-arvo castataan
pthread_exit( (void *)min );
}
// säie etsii suurimman arvon parametrina saamastaan globaalista taulukosta
// arvo palautetaan säikeen lopetuksen yhteydessä
void *max(void *arg){
int *values = (int *)arg;
int i;
int max = values[0];
for ( i=0; i < N; i++ )
if ( values[i] > max ) max = values[i];
// paluuarvon tyypin oltava void *, joten int-arvo castataan
pthread_exit( (void *)max );
}
Oletussäie luo aluksi taulukon ja arpoo sen täyteen lukuja. Tämän jälkeen
luodaan säikeet suorittaman suurimman ja pienimmän luvun etsiminen. Säikeiden
paluuarvo otetaan vastaan funktion pthread_join toisena parametrina.
int main(void){
pthread_t tid1, tid2;
int i, smallest, greatest;
// luodaan taulukko
int *values;
values = malloc( sizeof(int)*N);
// alustetaan satunnaislukugeneraattori
srand( time(NULL) );
// arvotaan taulukko täyteen lukuja väliltä 0-9999999
for ( i=0; i < N; i++ )
values[i] = rand()%10000000;
// taulukon osoite välitetään säikeille parametrina
pthread_create( &tid1, NULL, min, (void *)values );
pthread_create( &tid2, NULL, max, (void *)values );
pthread_join( tid1, (void **)&smallest );
pthread_join( tid2, (void **)&greatest );
printf("taulukon pienin %d ja suurin %d\n", smallest, greatest);
return 0;
}
Säikeen lopetuksen yhteydessä palauttaman arvon vastaanottaminen tapahtuu
mielenkiintoisella tavalla. pthread_join:in toinen parametri on tyypiltään
void ** eli osoitin void osoittimeen. Tämä mahdollistaa sen, että säie voi
palauttaa osoitteen, joka täytyy ottaa vastaan osoittimena osoitteeseen.
Tällä kertaa paluuarvo on normaali int, joten funktiolle annetaan
parametriksi osoite muuttujaan, johon paluuarvo sijoitetaan, eli
&smallest, jotta kääntäjä on tyytyväinen, on tämä vielä castattava
void **-tyypiin.
void *saie(void *arg){
int *t;
// luodaan dynaamisesti neljän kokoinen int-taulukko
t = (int *)malloc( sizeof(int)*4 );
// täytetään taulukko
t[0] = 2;
t[1] = 5;
t[2] = 3;
t[3] = 8;
// palautetaan osoite varattuun muistialueeseen
pthread_exit( (void *)t );
}
int main(void){
pthread_t tid;
int i;
int *t;
pthread_create( &tid, NULL, saie, NULL );
// otetaan vastaan palautettu muistiosoite, parametri int-osoitteen osoite
pthread_join( tid, (void **)&t );
// tulostetaan taulukko
for ( i=0; i < 4; i++ )
printf("%d\n", t[i]);
return 0;
}
Eli pthrea_join:issa parametriksi annetaan osoite osoitinmuuttujaan.
Näin osoitinmuuttuja saa arvokseen säikeen palauttaman osoitteen.
HUOM: säie ei saa palauttaa osoitetta sisäiseen muuttujaansa! Osoitteen on
oltava joko mallocilla varattuun alueeseen tai globaaliin (eli funktioiden
ulkopuolella määriteltyyn) dataan.